The practise-oriented R case study that is mentioned towards the end of this post was also taken from a telecom example. At first glance, coming up with a churn rate is fairly easy and simple maths only. Measure the numbers of distinct customers / donors (or contracts or committed gifts) lost in a defined period (say, a month) and divide it by the number of customers / donors / contracts etc. at the beginning of this period. This is straightforward, simple in its application and can be easily explained – and is therefore a logical first step to tackle churn from an analytical standpoint. An interesting blog post from ecommerce platform provider Shopify offers a discussion on different aspects of churn calculation – and why things are not always as straightforward as they might seem at first glance. With regard to an inferential or predictive approach to churn, the blog KD Nuggets summarizes possible approaches and names two major streams:
KD Nuggets recommend not to focus too much on one modelling approach but to compare the (particularly predictive) performance of different models. Last, not least they recommend not to forget sound and in-depth explorative analyses as a first step. Will Kurt wrote a highly recommendable, relatively easy to read (caveat: Still take your time to digest it ...) blog post on how to approach churn using a stochastic model of customer population. Have a particular look at the Takeaway and Conclusion part. A summary attempt in one sentence: Although churn is random by its very nature (Brownian motion), suitable modelling will help you (based upon existing data) tell where your customer population will end up in the best and wort case (see picture below - 4.000 customer just will not be reached if we keep on going as we do now ...) 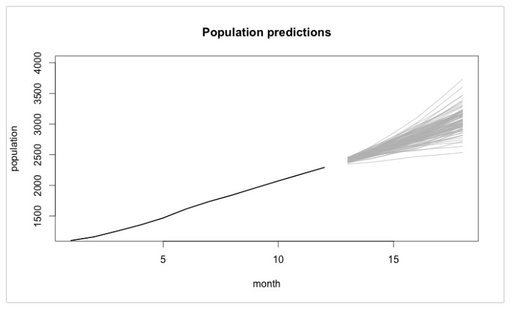 Last, not least, if you are interested in a case study from the telecom sector where a Logistic Regression Model was implemented with R, go and have a look at this blog post. The respective R code is also available at Github for the ones interested.
So – enjoy spring if you can and please don´t churn from this blog 😊.
2 Comments
Browsing through the web or attending conferences in the area of IT and marketing, one might get the impression that data science is ubiquitous. If somebody starts researching what data scientists actually do, they mostly come across terms like predictive modelling, machine learning and data mining. These terms sound sophisticated – and the activities they imply certainly are. However, apart from all modelling, algorithms and fancy tools it should not be overlooked what I think is a core task of a data scientist. They have to help people to understand data and support their decision making. To achieve this, data has to be presented in an understandable, “digestible” and convincing manner. This is where the field of data visualization comes into play which is an essential and indispensable aspect of doing data science. Data visualization was invented long before the IT revolution – you could actually say it was not so long after the French revolution. Charles Joseph Minard pioneered the graphical illustration of information in the first half of the 19th century. A lot of his work is still inspiring today. In 1869, when he was already retired, Minard produced a chart that many regard as one of the best data visualizations ever made. On the very left, it shows Napoleon Bonaparte’s Grande Armée at the start of the 1812 Russia campaign. The thickness of the line represents the size of the army. In addition to the size of the army, the visualization incorporates the distance travelled by the soldiers, the temperature, direction of travel, latitude and longitude and the relative location. That is tons of information integrated in one beautiful and graspable visualization!
|

