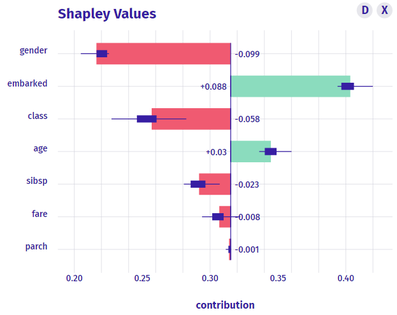
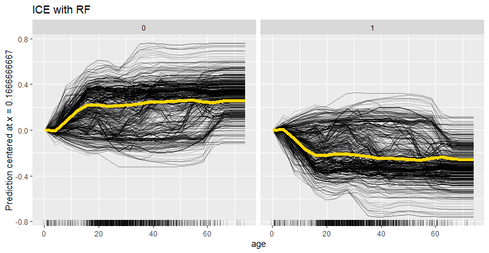
Ask your data
Blog
About & Contact
Blog
About & Contact